|
P4C
The P4 Compiler
|
|
P4C
The P4 Compiler
|
The back-end accepts only P4_16 code written for the ebpf_model.p4 or xdp_model.p4 filter models. It generates C code that can be afterwards compiled into eBPF (extended Berkeley Packet Filters) using clang/llvm or bcc.
An older version of this compiler for compiling P4_14 is available here (historical reference only).
Identifiers starting with ebpf_ are reserved in P4 programs, including for structure field names.
The ebpf_model.p4 target is a classifier-only: the program returns a boolean which controls whether the packet is passed or dropped. In P4 terms, this means there is no deparser.
The xdp_model.p4 target adds packet editing support, and is meant to replicate the capabilities of the Linux kernel's XDP environment. It can be viewed as an extension of the previous model which adds a deparser.
In this section we give a brief overview of P4 and EBPF. A detailed treatment of these topics is outside the scope of this text.
P4 is a domain-specific programming language for specifying the behavior of the dataplanes of network-forwarding elements. The name of the programming language comes from the title of a paper published in the proceedings of SIGCOMM Computer Communications Review in 2014: Programming Protocol-Independent Packet Processors
P4 itself is protocol-independent but allows programmers to express a rich set of data plane behaviors and protocols. This back-end only supports the newest version of the P4 programming language, P4_16. The core P4 abstractions are:
P4 programs describe the behavior of network-processing dataplanes. A P4 program is designed to operate in concert with a separate control plane program. The control plane is responsible for managing at runtime the contents of the P4 tables. P4 cannot be used to specify control-planes; however, a P4 program implicitly specifies the interface between the data-plane and the control-plane.
eBPF is a acronym that stands for Extended Berkeley Packet Filters. In essence eBPF is a low-level programming language (similar to machine code); eBPF programs are traditionally executed by a virtual machine that resides in the Linux kernel. eBPF programs can be inserted and removed from a live kernel using dynamic code instrumentation. The main feature of eBPF programs is their static safety: prior to execution all eBPF programs have to be validated as being safe, and unsafe programs cannot be executed. A safe program provably cannot compromise the machine it is running on:
eBPF programs are inserted into the kernel using hooks. There are several types of hooks available:
foo() will cause the eBPF program to execute every time some kernel thread executes foo().eBPF programs can be used for many purposes; the main use cases are dynamic tracing and monitoring, and packet processing. We are mostly interested in the latter use case in this document.
The eBPF runtime exposes a bi-directional kernel-userspace data communication channel, called tables (also called maps in some eBPF documents and code samples). eBPF tables are essentially key-value stores, where keys and values are arbitrary fixed-size bitstrings. The key width, value width and table size (maximum number of entries that can be stored) are declared statically, at table creation time.
In user-space tables handles are exposed as file descriptors. Both user- and kernel-space programs can manipulate tables, by inserting, deleting, looking up, modifying, and enumerating entries in a table.
In kernel space the keys and values are exposed as pointers to the raw underlying data stored in the table, whereas in user-space the pointers point to copies of the data.
An important aspect to understand related to eBPF is the execution model. An eBPF program is triggered by a kernel hook; multiple instances of the same kernel hook can be running simultaneously on different cores.
Each table however has a single instances across all the cores. A single table may be accessed simultaneously by multiple instances of the same eBPF program running as separate kernel threads on different cores. eBPF tables are native kernel objects, and access to the table contents is protected using the kernel RCU mechanism. This makes access to table entries safe under concurrent execution; for example, the memory associated to a value cannot be accidentally freed while an eBPF program holds a pointer to the respective value. However, accessing tables is prone to data races; since eBPF programs cannot use locks, some of these races often cannot be avoided.
eBPF and the associated tools are also under active development, and new capabilities are added frequently.
From the above description it is apparent that the P4 and eBPF programming languages have different expressive powers. However, there is a significant overlap in their capabilities, in particular, in the domain of network packet processing. The following image illustrates the situation:
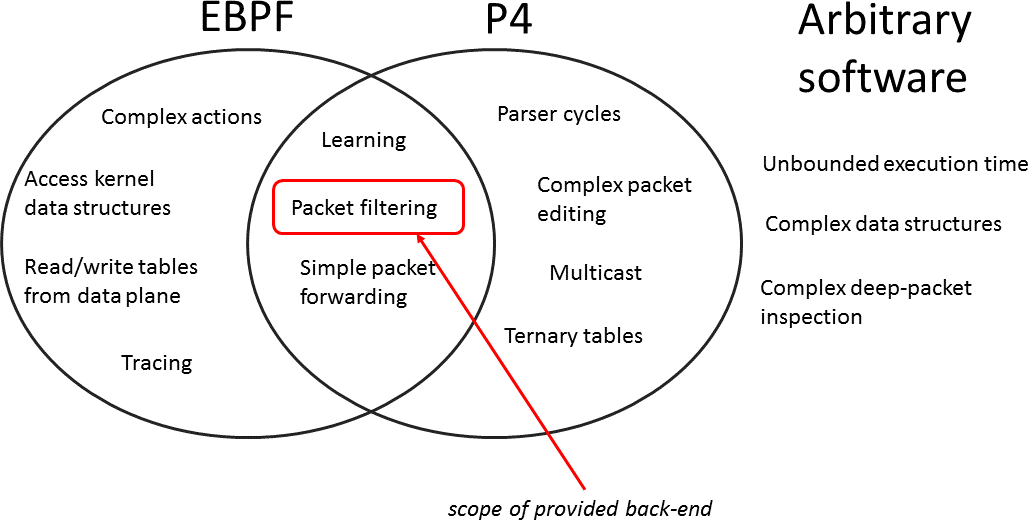
We expect that the overlapping region will grow in size as both P4 and eBPF continue to mature.
The current version of the P4 to eBPF compiler translates programs written in the version P4_16 of the programming language to programs written in a restricted subset of C. The subset of C is chosen such that it should be compilable to eBPF using clang and/or bcc (the BPF Compiler Collection).
The P4 program only describes the packet processing data plane, that runs in the Linux kernel. The control plane must be separately implemented by the user. BCC tools simplify this task considerably, by generating C and/or Python APIs that expose the dataplane/control-plane APIs.
Our eBPF programs require a Linux kernel with version 4.15 or newer. The eBPF backend relies on libbpf, which provides kernel- and distribution-independent header files. libbpf must be available in order to compile the generated eBPF C code into eBPF byte code. To install libbpf, run python3 backends/ebpf/build_libbpf in the p4c folder.
In addition the following packages and programs are required to run the full test suite:
clsact to load eBPF programs via tc and ip.Additionally, the eBPF compiler test suite has the following python dependencies:
You can install these using:
The current version of the P4 to eBPF compiler supports a relatively narrow subset of the P4 language, but still powerful enough to write very complex packet filters and simple packet forwarding engines. We expect that the compiler's capabilities will improve gradually.
Here are some limitations imposed on the P4 programs:
To simplify the translation, the P4 programmer should refrain using identifiers whose name starts with ebpf_.
The following table provides a brief summary of how each P4 construct is mapped to a corresponding C construct:
| P4 Construct | C Translation |
|---|---|
header | struct type with an additional valid bit |
struct | struct |
| parser state | code block |
| state transition | goto statement |
extract | load/shift/mask data from packet buffer |
| P4 Construct | C Translation |
|---|---|
| table | 2 eBPF tables: second one used just for the default action |
| table key | struct type |
table actions block | tagged union with all possible actions |
action arguments | struct |
table reads | eBPF table access |
action body | code block |
table apply | switch statement |
| counters | additional eBPF table |
The C code can be generated using the following command:
p4c-ebpf PROGRAM.p4 -o out.c
This will generate the C-file and its corresponding header. The architecture (ebpf_model or xdp_model) is auto-detected.
The resulting file contains the complete data structures, tables, and a C function named ebpf_filter that implements the P4-specified data-plane. This C file can be manipulated using clang or BCC tools; please refer to the BCC project documentation and sample test files of the P4 to eBPF source code for an in-depth understanding.
The general C-file alone will not compile. It depends on headers specific to the generated target. For the default target, this is the kernel_ebpf.h file which can be found in the P4 backend under p4c/backends/ebpf/runtime. The P4 backend also provides a makefile and sample header which allow for quick generation and automatic compilation of the generated file.
make -f p4c/backends/ebpf/runtime/kernel.mk BPFOBJ=out.o P4FILE=PROGRAM.p4
where -f path is the path to the makefile, BPFOBJ is the output ebpf byte code and P4FILE is the input P4 program. This command sequence will generate an eBPF program, which can be loaded into the kernel using TC.
The eBPF code that is generated is can be used as a classifier attached to the ingress packet path using the Linux TC subsystem. The same eBPF code should be attached to all interfaces. Note however that all eBPF code instances share a single set of tables, which are used to control the program behavior.
tc qdisc add dev IFACE clsact
Creates a classifier qdisc on the respective interface. Once created, eBPF programs can be attached to it using the following command:
tc filter add dev IFACE egress bpf da obj YOUREBPFCODE section prog verbose
da implies that tc takes action input directly from the return codes provided by the eBPF program. We currently support TC_ACT_SHOT and TC_ACT_OK. More information avaiable here.
Once the eBPF program is loaded, various methods exist to manipulate the tables. The easiest and simplest way is to use the bpftool provided by the kernel.
An alternative is to use explicit syscalls (an example can be found in the kernel tools folder.
The P4 compiler automatically provides a set of table initializers, which may also serve as example, in the header of the generated C-file.
The following tests run ebpf programs:
make check-ebpf: runs the basic ebpf user-space testsmake check-ebpf-bcc: runs the user-space tests using bcc to compile ebpfsudo -E make check-ebpf-kernel: runs the kernel-level tests. Requires root privileges to install the ebpf program in the Linux kernel. Note: by default the kernel ebpf tests are disabled; if you want to enable them you can modify the file backends/ebpf/CMakeLists.txt by setting this variable to True: set (SUPPORTS_KERNEL True)The P4 to eBPF compiler comes with the support for custom C extern functions. It means that a developer can write a custom, eBPF-compatible (acceptable by BPF verifier) C function and call it from the P4 program as a normal P4 action. As a result, P4 program can be extended with functionality, which is not supported natively by the P4 language. This feature is briefly described below.
The C extern function can effectively enhance the functionality of P4 program. A programmer should be able to write own function, declare it in the P4 program and invoke from within P4 action or P4 control block.
The C extern can use BPF helpers in order to make syscalls to eBPF subsystem. In particular, the C extern can define and have control over its own set of BPF maps. However, the C extern must not read or write to BPF maps implementing P4 tables and used by the main P4 program.
The C extern could be also allowed to access packet’s payload, but this feature is not implemented in the first version of the C Custom Externs feature.
The custom C extern function should be explicitly declared in the P4 program making use of that extern. For example:
The --emit-externs flag must be appended to the p4c-ebpf compiler to instruct it that there are some C extern functions defined in the P4 program and compiler should not warn about them.
Furthermore, the C file including definition of the C extern function should be provided to clang:
Using BPF maps:
The backends/ebpf/psa directory implements PSA (Portable Switch Architecture) for the eBPF backend.
ebpf_model. Please, get familiar with the base eBPF backend first.The PSA to eBPF compiler provides two flavors of generated eBPF code: TC-based design and XDP-based design. The TC-based design leverages eBPF TC (Traffic Control) hook and is able to implement any PSA program. The XDP-based design offloads packet processing to eBPF XDP (eXpress Data Path) hook and provides better performance than the TC-based flavor. However, the XDP-based design lacks support for packet recirculation, QoS (no integration with TC qdisc) and CLONE_E2E packet path.
P4 packet processing is translated into a set of eBPF programs attached to the TC hook. The eBPF programs implement packet processing defined in a P4 program written according to the PSA model. The TC hook is used as a main engine, because it enables a full implementation of the PSA specification. The XDP-based version of the PSA implementation does not implement the full specification, but provides better performance.
The TC-based design of PSA for eBPF is depicted in Figure below.
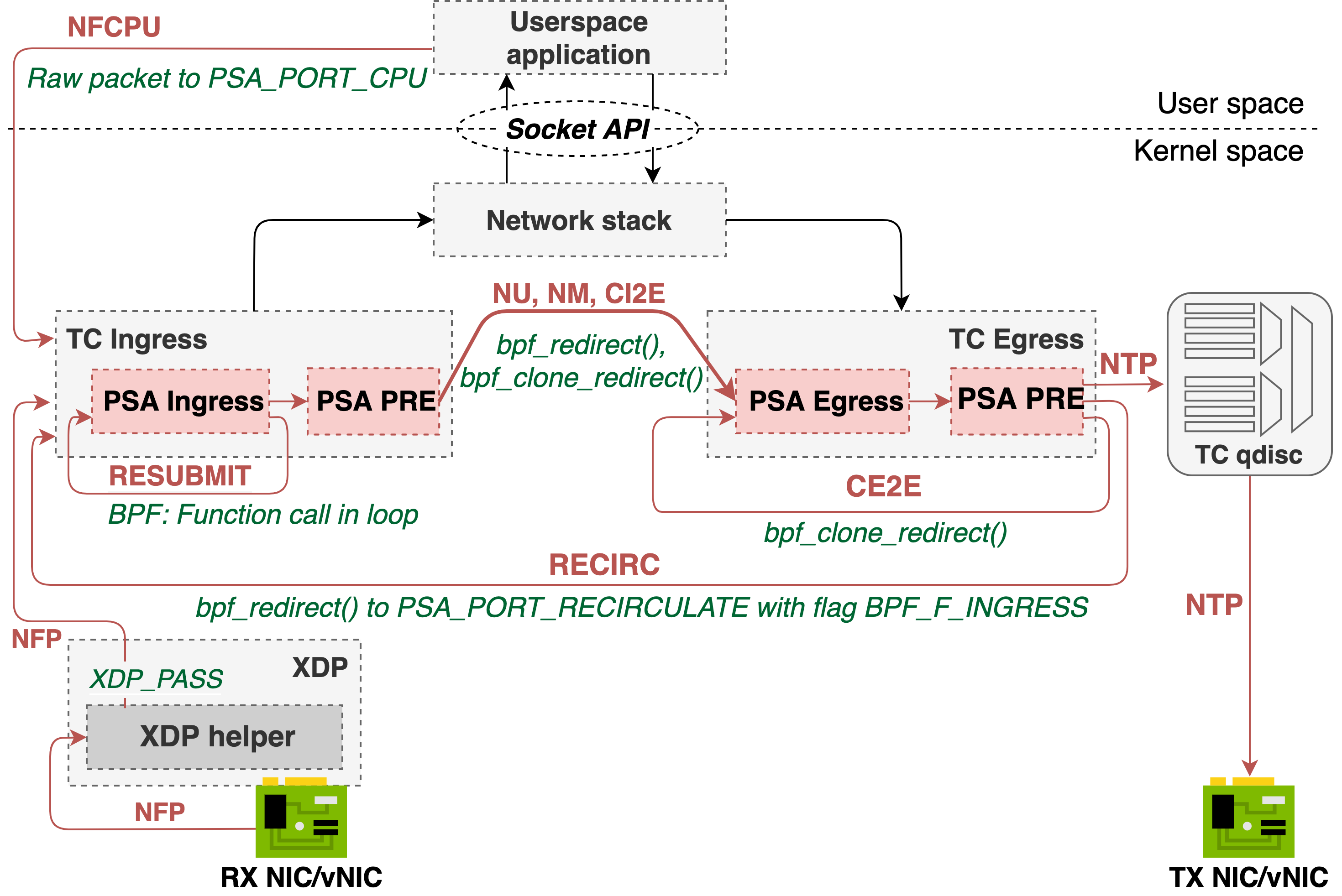
xdp-helper - the fixed, non-programmable "helper" program attached to the XDP hook. The role of the xdp-helper program is to prepare a packet for further processing in the TC subsystem. Why do we need the XDP helper program? Some eBPF helpers for the TC hook depend on the skb->protocol type (in particular, IPv4/IPv6 EtherType), which is read by the TC layer before a packet enters the eBPF program. This limitation prevents from using TC as a protocol-independent packet processing engine. If a packet arriving at the XDP level isn't an IPv4 packet, the XDP helper replaces it's original EtherType with IPv4 EtherType. The original EtherType is passed to TC according to the XDP2TC mode specified by a user (see XDP2TC metadata section). The tc-ingress program reads original EtherType and puts it back into the packet. We verified that this workaround enables handling other protocols in the TC layer (e.g., MPLS).tc-ingress - In the TC Ingress, the PSA Ingress pipeline as well as so-called "Traffic Manager" eBPF program is attached. The Ingress pipeline is composed of Parser, Control block and Deparser. The details of Parser, Control block and Deparser implementation will be explained further in this document. The same eBPF program in TC contains also the Traffic Manager. The role of Traffic Manager is to redirect traffic between the Ingress (TC) and Egress (TC). It is also responsible for packet replication via clone sessions or multicast groups and sending packet to CPU.tc-egress - The PSA Egress pipeline (composed of Parser, Control block and Deparser) is attached to the TC Egress hook. As there is no XDP hook in the Egress path, the use of TC is mandatory for the egress processing. Note! If the PSA Egress pipeline is not used (i.e. it is left empty by a developer), the PSA-eBPF compiler will not generate the TC Egress program. This brings a noticeable performance gain, if the egress pipeline is not used.The XDP-based design of PSA for eBPF is depicted in Figure below.
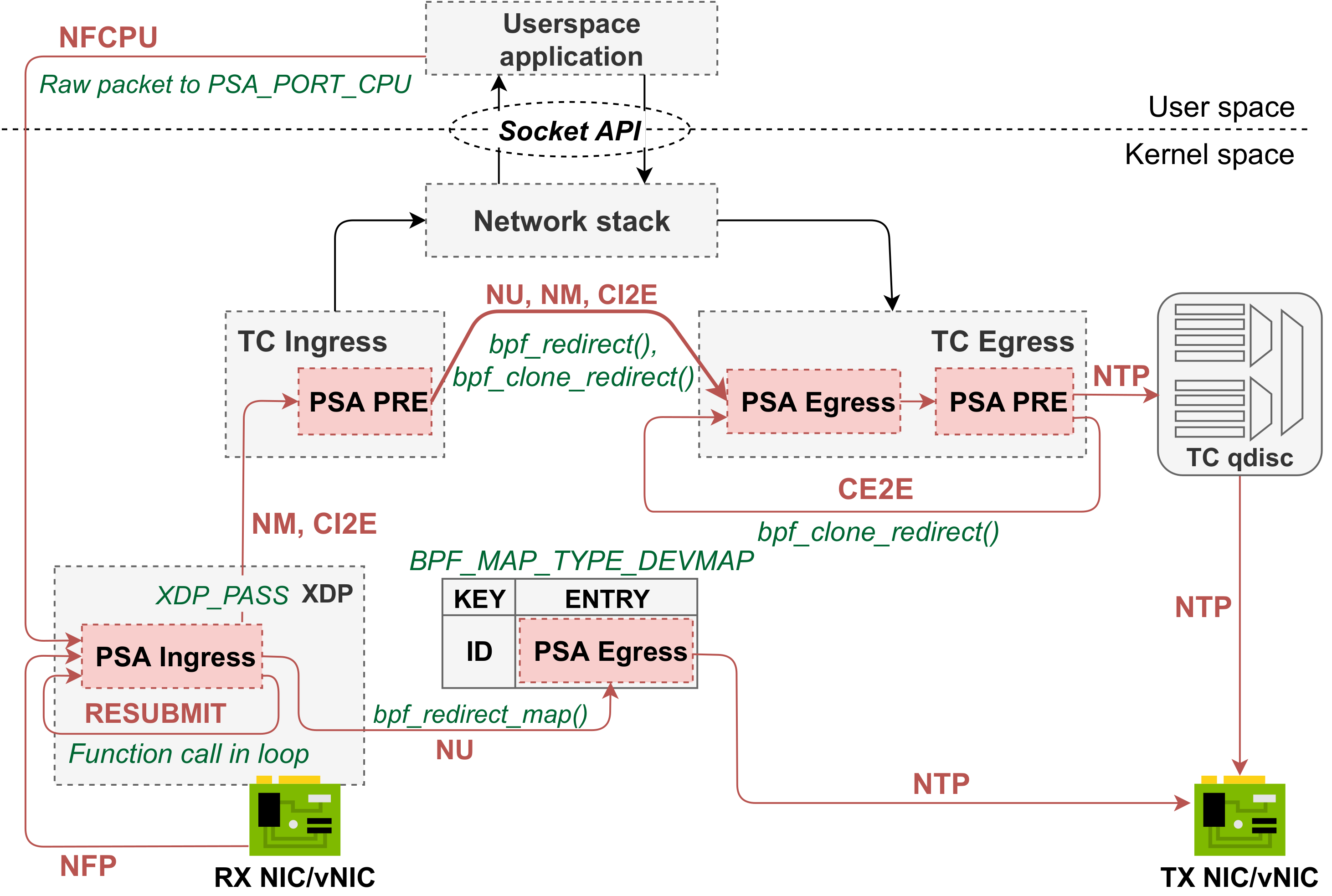
xdp-helper does not exist in this design, instead the PSA Ingress pipeline is attached to XDP hook. Since XDP does not provide a hook on the egress path, we mimic the PSA Egress pipeline by using eBPF program attached to BPF_MAP_TYPE_DEVMAP, a special type of BPF map used to perform packet redirection with bpf_redirect_map() helper. Also, XDP hook in the currently supported kernel version (up to 5.13) does not support packet cloning. Therefore, packets to be cloned are passed up to the TC hook, where the Packet Replication Engine is implemented. Once a packet reaches the TC hook, it is further processed by TC exclusively. Thus, the PSA-eBPF compiler generates a TC Egress program, which is a mirror reflection of the PSA Egress pipeline attached to the XDP DEVMAP. The packets to be cloned are passed up to TC with additional metadata. The mechanism used to transfer the metadata depends on the XDP2TC mode, we support cpumap and head modes for XDP-based design (meta mode is not supported).
There is no difference (comparing to TC-based design) in how PSA externs, P4 match kinds and parser primitives are implemented for XDP-based design.
To compile P4 programs for XDP, use --xdp compiler option.
WARNING! The NTK packet path is a custom packet path used for the PSA-eBPF only! It is not a standardized PSA packet path.
The NTK packet path allows integrating P4/PSA programs for eBPF with the standard Linux kernel stack. The main use case is handling ICMP/ARP requests and sending packet to the userspace process listening on a socket.
The NTK path is enforced if drop is set to false and egress_port is left unchanged or set to 0 (it's a special implicit port number that forwards packets to the kernel stack). Since packets can be modified in the PSA ingress pipeline before they are sent to the kernel stack, a P4 programmer should make sure that packets use standard headers and are properly formatted. Otherwise, the kernel stack will drop them.
NOTE! There is no symmetric packet path from kernel - once a packet enters the kernel network stack, it is further processed exclusively by the kernel. As a consequence, all packets that have not been processed by the PSA Ingress pipeline (e.g., packets sent from userspace application) will not be handled by the PSA Egress pipeline!
TC-based design
Packet arriving on an interface is intercepted in the XDP hook by the xdp-helper program. It performs pre-processing and packet is passed for further processing to the TC ingress. Note that there is no P4-related processing done in the xdp-helper program.
By default, a packet is further passed to the TC subsystem. It is done by XDP_PASS action and packet is further handled by tc-ingress program.
XDP-based design
No specific processing is done. Packets are just received by the eBPF programm attached to XDP.
The purpose of RESUBMIT is to transfer packet processing back to the Ingress Parser from Ingress Deparser.
We implement packet resubmission by calling main ingress() function (implementing the PSA Ingress pipeline) in a loop. The MAX_RESUBMIT_DEPTH variable specifies maximum number of resubmit operations (the MAX_RESUBMIT_DEPTH value is currently hardcoded and is set to 4). The resubmit flag defines whether the tc-ingress program should enter next iteration (resubmit) or break the loop. The pseudocode looks as follows:
The same mechanism for RESUBMIT is used in the TC-based and XDP-based design.
TC-based design
NU, NM and CI2E refer to process of sending packet from the PSA Ingress Pipeline (more specifically from the Traffic Manager) to the PSA Egress pipeline. The NU path is implemented in the eBPF subsystem by invoking the bpf_redirect() helper from the tc-ingress program. This helper sets an output port for a packet and the packet is further intercepted by the TC egress.
Both NM and CI2E require the bpf_clone_redirect() helper to be used. It redirects a packet to an output port, but also clones a packet buffer, so that a packet can be copied and sent to multiple interfaces. From the eBPF program's perspective, bpf_clone_redirect() must be invoked in the loop to send packets to all ports from a clone session/multicast group.
Clone sessions or multicast groups and theirs members are stored as a BPF array map of maps (BPF_MAP_TYPE_ARRAY_OF_MAPS). The P4-eBPF compiler generates two outer BPF maps: multicast_grp_tbl and clone_session_tbl. Both of them store inner maps indexed by the clone session or multicast group identifier, respectively. The clone session/multicast group members (defining egress_port, instance or other parameters used by clone sessions) are stored in the inner hash map.
While performing the packet replication, the eBPF program does a lookup to the outer map based on the clone session/multicast group identifier and, then, does another lookup to the inner map to find all members.
XDP-based design
The NU path is implemented by calling bpf_redirect_map() after the ingress processing is completed. The NM and CI2E paths are not possible in the XDP layer. Packets marked to be cloned are sent up to the TC hook with additional metadata (e.g., parsed headers) and they are cloned by the eBPF program attached to the TC Ingress by using bpf_clone_redirect(). The clone sessions and multicast groups are implemented exactly like for the TC-based design.
TC-based design
CE2E refers to process of copying a packet that was handled by the Egress pipeline and resubmitting the cloned packet to the Egress Parser.
CE2E is implemented by invoking bpf_clone_redirect() helper in the Egress path. Output ports are determined based on the clone_session_id and lookup to "clone_session" BPF map, which is shared among TC ingress and egress (eBPF subsystem allows for map sharing between programs).
XDP-based design
CE2E is not supported by the XDP-based design.
The PSA implementation for eBPF backend assumes a special interface called PSA_PORT_CPU that is used for communication between a control plane application and data plane. Sending packet to CPU does not differ significantly from normal packet unicast. A control plane application should listen for new packets on the interface identified by PSA_PORT_CPU in a P4 program. By redirecting a packet to PSA_PORT_CPU in the Ingress pipeline the packet is forwarded via Traffic Manager to the Egress pipeline and then, sent to the "CPU" interface.
The mechanism is common for both design options (TC/XDP).
TC-based design
Packets from tc-egress are sent out to the egress port. The egress port is determined in the Ingress pipeline and is not changed in the Egress pipeline.
Note that before a packet is sent to the output port, it's processed by TC qdisc first. The TC qdisc is the Linux QoS engine. The eBPF programs generated by P4-eBPF compiler sets skb->priority value based on the PSA class_of_service metadata. The skb->priority is used to interact between eBPF programs and TC qdisc. A user can configure different QoS behaviors via TC CLI and send a packet from PSA pipeline to a specific QoS class identified by skb->priority.
XDP-based design
Packets from the XDP egress program attached to BPF_DEVMAP are directly sent out to the egress port. There is no equivalent of Buffering & Queueing Engine in the XDP-based design.
TC-based design
The purpose of RECIRCULATE is to transfer packet processing back from the Egress Deparser to the Ingress Parser.
In order to implement RECIRCULATE we assume the existence of PSA_PORT_RECIRCULATE ports. Therefore, packet recirculation is simply performed by invoking bpf_redirect() to the PSA_PORT_RECIRCULATE port with BPF_F_INGRESS flag to enforce processing a packet by the Ingress pipeline.
XDP-based design
The RECIRCULATE path is not supported by the XDP-based design.
There are some global metadata defined for the PSA architecture. For example, packet_path must be shared among different pipelines. To share a global metadata between pipelines we use skb->cb (control buffer), which gives us 20B that are free to use.
The XDP2TC mode determines how the metadata (containing original EtherType) is passed from XDP up to TC. By default, PSA-eBPF uses the bpf_xdp_adjust_meta() helper to append the original EtherType to the skb’s data_meta field, which is further read by the TC Ingress to restore the original format of the packet. The way of passing metadata is determined by the user-configurable --xdp2tc compiler flag. We have noticed that some NIC drivers does not support the bpf_xdp_adjust_meta() BPF helper and the default mode cannot be used. Therefore, we come up with a more generic mode called head, which uses bpf_xdp_adjust_head() instead to prepend a packet with metadata. In this mode, the helper must be invoked twice - in the XDP helper program to append the metadata and in the TC Ingress to strip the metadata out of a packet. We also introduce the third mode - cpumap, which is an experimental features and should be used carefully. The cpumap assumes that the single CPU core handles a packet in the run-to-completion mode from XDP up to the TC layer (in other words, for a given packet, the CPU core running the TC program is the same as the one for XDP). If the above condition is met, the cpumap mode uses the per-CPU BPF array map to transfer metadata from XDP to TC. Hence, the cpumap mode should only be used, if there is a guarantee that the same CPU core handles the packet in both XDP and TC hooks. Note that the XDP helper program introduces a constant but noticeable per-packet overhead. Though, it is necessary to implement P4 processing in the TC layer.
To sum up, the --xdp2tc compiler flag can take the following values:
meta (default) - uses the bpf_xdp_adjust_meta() BPF helper. It's the most efficient way and should be used wherever possible.head - uses the bpf_xdp_adjust_head() BPF helper and should be used if meta is not supported by a NIC driver.cpumap - uses the BPF per-CPU array map. It should rather be used for testing purposes only.The PSA-eBPF compiler assumes that any control plane software managing eBPF programs generated by the P4 compiler must be in line with the Control-plane API (a kind of contract or set of instructions that must be followed to make use of PSA-eBPF programs). The Control-plane API is summarized below, but we suggest using the NIKSS API that already implements the control-plane API and exposes higher level C API.
libbpf loader and are annotated with BTF. All eBPF objects (programs, maps) must be pinned to the BPF filesystem under /sys/fs/bpf/. Once eBPF objects are loaded and pinned, a control plane application must invoke map_initialize() BPF function - it can be done using bpf_prog_test_run. The map_initialize() function is auto-generated by the PSA-eBPF compiler and configures all initial state, i.e. it initializes default actions, const entries, etc.struct for BPF map's key and value. (e.g. ingress_tbl_fwd_key and ingress_tbl_fwd_value). The exact match table is implemented as BPF hash map. The lpm match table is implemented as BPF LPM_TRIE. Both key and value fields must be provided in the host byte order.BPF_MAP_TYPE_ARRAY_OF_MAPS) in the eBPF subsystem. Each entry of an outer map represents a single clone session or multicast group. An inner map is a hash map storing clone session/multicast group members, according to the structure defined by struct list_key_t (BPF map key) and struct element (value). To add a new clone session/mutlicast group, a control plane must add a new element to the outer map (indexed by clone session or multicast group identifier referenced by clone_session_id or multicast_group in a PSA program) and initialize an inner map. To add a new clone session/multicast group member, a con1trol plane must add new element to the inner map.The PSA-eBPF compiler currently supports the following P4 match kinds: exact, lpm, ternary.
An exact table is implemented using the BPF hash map. A P4 table is considered an exact table if all its match fields are defined as exact. Then, the PSA-eBPF compiler generates a BPF hash map instance for each P4 table instance. The hash map key as a concatenation of P4 match fields translated to eBPF representation. Each apply() operation is translated into a lookup to the BPF hash map. The value is used to determine an action and its parameters.
An lpm table is implemented using the BPF LPM_TRIE map. A P4 table is considered an lpm table if it contains a single lpm field and no ternary fields. The PSA-eBPF compiler generates a BPF LPM_TRIE map instance for each P4 table instance. The hash map key as a concatenation of P4 match fields translated to eBPF representation. Moreover, the PSA-eBPF compiler shuffles the match fields and places the lpm field in the last position. Each apply() operation is translated into a lookup to the LPM_TRIE map. A control plane should populate the LPM_TRIE map with entries composed of a value and prefix.
There is no built-in BPF map for ternary (wildcard) matching. Hence, the PSA-eBPF compiler leverages the Tuple Space Search (TSS) algorithm for ternary matching (refer to the research paper to learn more about the TSS algorithm). A ternary table is implemented using a combination of hash and array BPF maps that realizes the TSS algorithm. A P4 table is considered a ternary table if it contains at least one ternary field (exact and lpm fields are converted to ternary fields with an appropriate mask).
Note! The PSA-eBPF compiler requires match keys in a ternary table to be sorted by size in descending order.
The PSA-eBPF compiler generates 2 BPF maps for each ternary table instance (+ the default action map):
<TBL-NAME>_prefixes map is a BPF hash map that stores all unique ternary masks. The ternary masks are created based on the runtime table entries that are installed by a user.<TBL-NAME>_tuples_map map is a BPF array map of maps that stores all "tuples". A single tuple is a BPF hash map that stores all flow rules with the same ternary mask.Note that the nikss-ctl table add CLI command greatly simplifies the process of adding/removing flow rules to ternary tables.
For each apply() operation, the PSA-eBPF compiler generates the piece of code performing lookup to the above maps. The lookup code iterates over the <TBL-NAME>_prefixes map to retrieve a ternary mask. Next, the lookup key (a concatenation of match keys) is masked with the obtained ternary mask and lookup to a corresponding tuple map is performed. If a match is found, the best match with the highest priority is saved, and the algorithm continues to examine other tuples. If an entry with a higher priority is found, the best match is overwritten. The algorithm exists when there is no more tuples left.
The snippet below shows the C code generated by the PSA-eBPF compiler for a lookup into a ternary table. The steps are explained below.
The description of annotated lines:
MAX_INGRESS_TBL_TERNARY_1_KEY_MASKS which is configured by --max-ternary-masks compiler option (defaults to 128). Note that the eBPF program complexity (instruction count) depends on this constant, so some more complex P4 program may not compile if the max ternary masks value is too high (see the Limitations section).<TBL-NAME>_prefixes map. Note that the key is masked in 4-byte chunks.<TBL-NAME>_tuples_map outer BPF map is done to find a tuple map based on the tuple ID. The lookup returns the inner BPF map, which stores all entries related to a tuple.Note that the TSS algorithm has linear O(n) packet classification complexity, where "n" is a number of unique ternary masks.
ActionProfile is a table implementation that separates actions (and its parameters) from a P4 table, introducing a level of indirection. The P4-eBPF compiler generates an additional BPF hash map, if the Action Profile is specified for a P4 table. The additional BPF map stores the mapping between the ActionProfile member reference and a P4 action specification. During the lookup to the P4 table with Action Profile, eBPF program first queries the first BPF map using the match key composed from the packet fields and expects the ActionProfile member reference to be returned. Next, the eBPF programs uses the obtained member reference as a lookup key to a second map to retrieve the action specification. Hence, the eBPF program does one additional lookup to the additional BPF map, if the ActionProfile is specified for a P4 table.
ActionSelector is a table implementation similar to an ActionProfile, but extends its functionality with support for groups of actions. If a table entry contains a member reference, the ActionSelector behaves in the same way as an ActionProfile. In case of group references, the PSA-eBPF compiler generates additional BPF maps. One of additional BPF maps (hash map of maps) maps a group reference ID to an inner map that contains a group of entries. The inner map (might be created at runtime by nikss-ctl) stores a number of all members in a group as the first element of the inner map. The rest of entries contains members of the ActionSelector group. To choose a member from a group, a checksum is calculated from all selector match keys. Next, the obtained member from the group map is used to get and execute an action.
The second compiler-created map contains an action for an empty group. For the ActionSelector, there are two fields stored in a table that uses given ActionSelector instance, one is reference, second is marker whether reference points to group or member.
Before action execution, following source code will be generated (and some additional comments to it) for table lookup, which has implementation ActionSelector:
Description of marked lines:
_is_group_ref field is non-zero, the reference is assumed to be a group reference.ActionSelector._actions map._defaultActionGroup table.To manage the ActionSelector instance (do not confuse with a table that uses this implementation), you can use nikss-ctl action-selector command or C API from NIKSS.
Digests are intended to carry a small piece of user-defined data from the data plane to a control plane. The PSA-eBPF compiler translates each Digest instance into BPF_MAP_TYPE_QUEUE that implements a FIFO queue. If a deparser triggers the pack() method, an eBPF program inserts data defined for a Digest into the BPF queue map using bpf_map_push_elem. A user space application is responsible for performing periodic queries to this map to read a Digest message. It can use either nikss-ctl digest get pipe, nikss_digest_get_next from NIKSS C API or bpf_map_lookup_and_delete_elem from libbpf API.
Meters are a mechanism for "marking" packets that exceed an average packet or bit rate. Meters implement Dual Token Bucket Algorithm with both "color aware" and "color blind" modes. The PSA-eBPF implementation uses a BPF hash map to store a Meter state. The current implementation in eBPF uses BPF spinlocks to make operations on Meters atomic. The bpf_ktime_get_ns() helper is used to get a packet arrival timestamp.
The best way to configure a Meter is to use nikss-ctl meter tool as in the following example:
nikss-ctl accepts PIR and CIR values in bytes/s units or packets/s. PBS and CBS in bytes or packets.
Direct Meter is always associated with the table entry that matched. The Direct Meter state is stored within the table entry value.
value_set is a P4 lang construct allowing to determine next parser state based on runtime values. The P4-eBPF compiler generates additional hash map for each ValueSet instance. In select case expression each select() on ValueSet is translated into a lookup into the BPF hash map to check if an entry for a given key exists. A value of the BPF map is ignored.
The Random extern is a mean to retrieve a pseudo-random number in a specified range within a P4 program. The PSA-eBPF compiler uses the bpf_get_prandom_u32() BPF helper to get a pseudo-random number. Each read() operation on the Random extern in a P4 program is translated into a call to the BPF helper.
Follow standard steps for the P4 compiler to install the eBPF backend with the PSA support.
The PSA implemented for eBPF backend is verified to work with the kernel version 5.8+ and x86-64 CPU architecture. Moreover, make sure that the BPF filesystem is mounted under /sys/fs/bpf.
Also, make sure you have the following packages installed:
You should also install a static libbpf library. Run the following commands:
You can compile a P4-16 PSA program for eBPF in a single step using:
You can also perform compilation step by step:
Note that you can use -mcpu flag to define the eBPF instruction set. Visit this blog post to learn more about eBPF instruction sets.
The above steps generate out.o BPF object file that can be loaded to the kernel.
Supposing we want to use a packet recirculation we have to specify the PSA_PORT_RECIRCULATE port. We can use -DPSA_PORT_RECIRCULATE=<RECIRCULATE_PORT_IDX> Clang flag via kernel.mk
or directly: clang ... -DPSA_PORT_RECIRCULATE=<RECIRCULATE_PORT_IDX> ...,
where RECIRCULATE_PORT_IDX is a number of a psa_recirc interface (this number can be obtained from ip -n switch link).
By default PSA_PORT_RECIRCULATE is set to 0.
We provide the NIKSS C API and the nikss-ctl CLI tool that can be used to manage eBPF programs generated by P4-eBPF compiler. To install the CLI tool, follow the guide in the NIKSS repository. Use nikss-ctl help to get all possible commands.
Note! Although eBPF objects can be loaded and managed by other tools (e.g. bpftool), we recommend using nikss-ctl. Some features (e.g., default actions) will only work when using nikss-ctl.
To load eBPF programs generated by P4-eBPF compiler run:
PIPELINE-ID is a user-defined value used to uniquely identify PSA-eBPF pipeline (we are going to support for multiple PSA-eBPF pipelines running in parallel). In the next step, for each interface that should be attached to PSA-eBPF run:
PSA implementation for eBPF backend is covered by a set of PTF tests that verify a correct behavior of various PSA mechanisms. The test scripts, PTF test cases and test P4 programs are located under backends/ebpf/tests. The tests must be executed from this directory.
To run all PTF tests:
You can also specify a single PTF test to run:
It might be also useful to enable tracing for troubleshooting with bpftool prog tracelog:
The PSA implementation for eBPF backend generates standard BPF objects that can be inspected using bpftool.
To troubleshoot PSA-eBPF program you will probably need bpftool. Follow the steps below to install it.
You should be able to see bpftool help:
Refer to the bpftool guide for more examples how to use it.
Table caching optimizes P4 table lookups by adding a cache with all exact matches for time-consuming lookups including:
ternary (and/or lpm, exact) key - skip slow TSS algorithm if the key was matched earlier.lpm (and/or exact) key - skip slow LPM_TRIE map (especially when there is many entries) if the key was matched earlier.ActionSelector member selection from group - skip slow checksum calculation for selector key if it was calculated earlier.The fast exact-match map is added in front of each instance of a table that contains a lpm, ternary or selector match key. The table cache is implemented with BPF_MAP_TYPE_LRU_HASH, which shares its implementation with the BPF hash map. The LRU map provides a good lookup performance, but lower performance on map updates due to a maintenance process. Thus, this optimization fits into use cases, where a value of table key changes infrequently between packets.
This optimization may not improve performance in every case, so it must be explicitly enabled by compiler option. To enable table caching pass --table-caching to the compiler.
We list the known bugs/limitations below. Refer to the Roadmap section for features planned in the near future.
bpf_xdp_adjust_meta() isn't implemented by some NIC drivers, so the meta XDP2TC mode may not work with some NICs. So far, we have verified the correct behavior with Intel 82599ES. If a NIC doesn't support the meta XDP2TC mode you can use head or cpumap modes.lookahead() with bit fields (e.g., bit<16>) doesn't work.@atomic operation is not supported yet.psa_idle_timeout is not supported yet.xdp2tc=head mode works only for packets larger than 34 bytes (the size of Ethernet and IPv4 header).value_set only supports the exact match type and can only match on a single field in the select() expression.--max-ternary-masks (default: 128) is set to a high value, the P4 program may not load into the BPF subsystem due to the BPF complexity issue (the 1M instruction limit exceeded). This is the limitation of the current implementation of the TSS algorithm that requires iteration over BPF maps. Note that the recent kernel introduced the bpf_for_each_map_elem() helper that should simplify the iteration process and help to overcome the current limitation.ternary match fields, as BPF spinlocks are not allowed in inner maps of map-in-map.nikss library will remove all cached entries if it detects cache.All the below features are already implemented and will be contributed to the P4 compiler in subsequent pull requests.
select() expression.The below features are not implemented yet, but they are considered for the future extensions:
range match kind and there is a further investigation needed on how to implement range matching for eBPF programs.optional match kind yet. However, it can be implemented based on the same algorithm that is used for ternary matching.NIKSS API. We plan to integrate PSA-eBPF with the P4Runtime software stack (e.g., Stratum, TDI or P4-OvS).To report any other kind of problem, feel free to open a GitHub Issue or reach out to the project maintainers on the P4 Community Slack or via email.
Project maintainers: